Next Steps
Contents
Next Steps¶
If you’d like to get started with reproducing some of these insights where getting versed with Azure Machine
Learning, do follow the installation steps below, and learn more at the
Installation Steps¶
Setup the Environment¶
Pre-requisites: You need to have the Azure CLI installed, with the ml extension installed.
Create a virtualized environment and activate it.
Install the required python dependencies into this environment. With the included Makefile, once you are in the virtualized environment, you can run
make install.
Note: While you can install the python dependencies as per the
requirements.txt file, a more step-by-step approach is to install progressively as the scripts are run. Generally, that workflow is shown below:pip install python-dotenv(for environment variables)pip install azureml-core(for installing the base SDK of Azure ML)pip install azureml-dataset-runtime(particularly needed before running the upload of datasets)pip install pandas(needed before creating the simulated datasets)pip install azureml.pipeline(needed before triggering theml_pipeline.pyscript)pip install azureml.datadrift(before triggering the data drift monitor)
Ensure you have an environment variable file called
sub.envin your root, with the Azure subscription you are using listed in the file asSUB_ID=<your subscription>.
Run
make setup_run. This will trigger the creation of the basic Azure Machine Learning setup, followed by creation of the cluster, and uploading of the original raw dataset.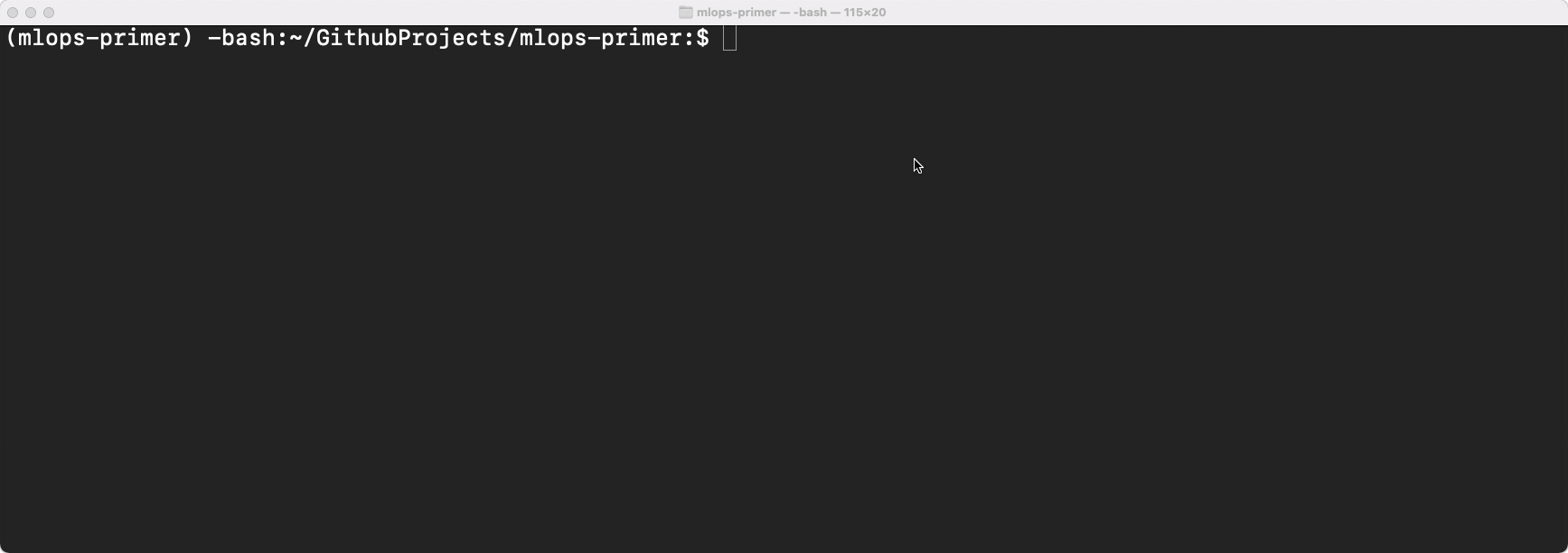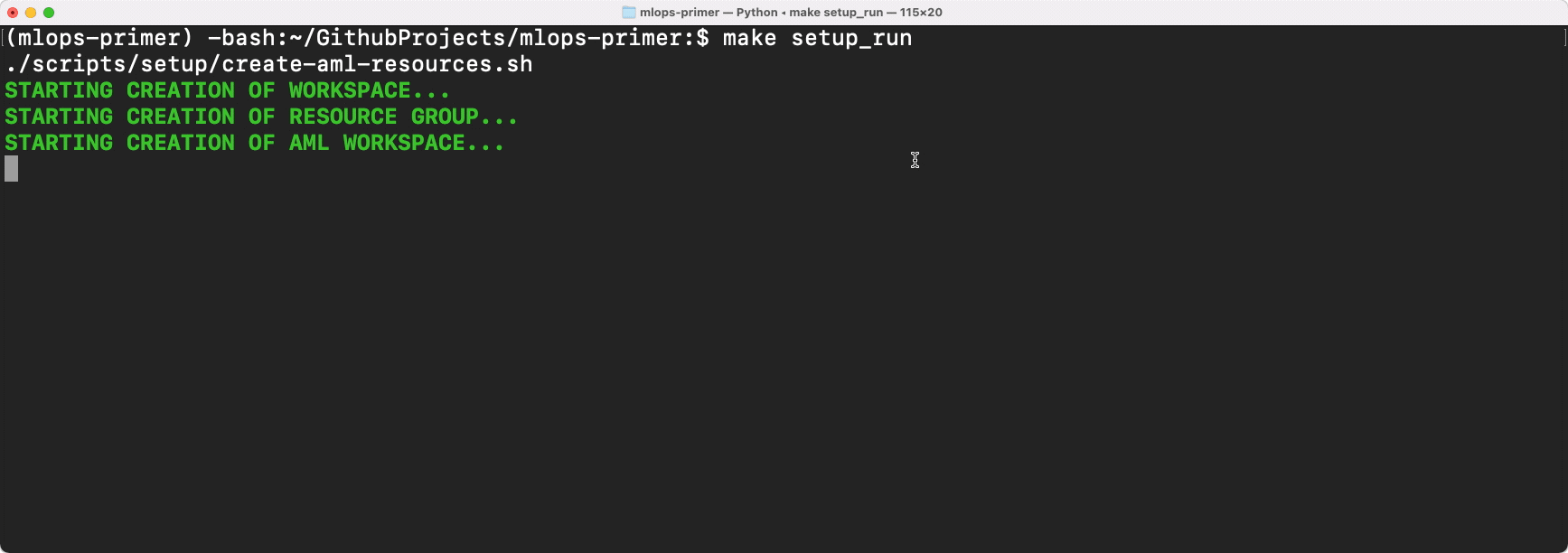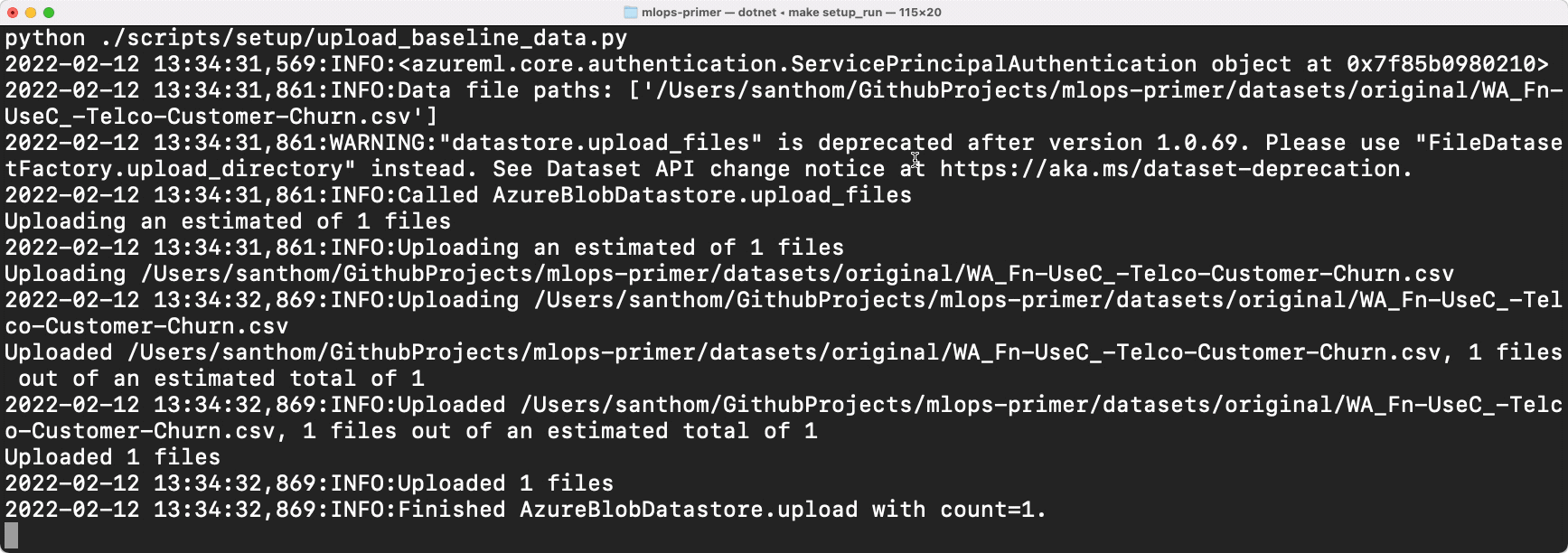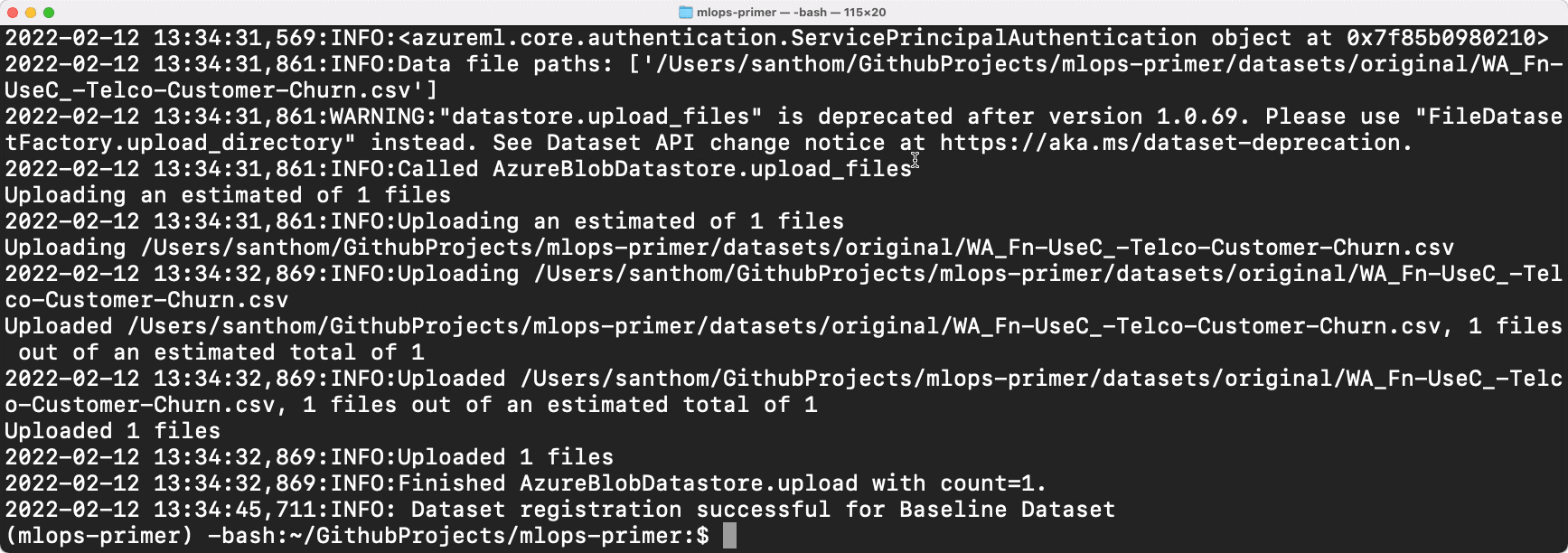
Key Workflows¶
Create the initial training pipeline run with
make create_pipeline.To train any of the retrain, data drift or concept drift scenarios, use the following commands:
For re-training,
make trigger_retrain.For data drift,
make trigger_ddrift.For concept drift,
make trigger_cdrift.